Designing AI for Multilingual Clarity
Summary
Gate agents routinely support passengers whose English proficiency varies, often during moments when timing, documentation, and boarding direction are operationally consequential. Today, that support depends heavily on informal workarounds—nearby multilingual coworkers, personal translation apps, gestures, repeated explanation, or escalation—creating inconsistent customer experiences and avoidable burden during peak gate operations. I led a mixed-method field evaluation of aiOla, an AI-based multilingual translation tool piloted in an airport gate environment, to understand whether it could support faster, clearer, and safer interactions between agents and non-English speaking passengers. The research combined live gate observations, post-demo interviews, post-use micro-feedback, semi-structured interviews, and an all-agent pulse survey across international and domestic gate contexts. The study showed that AI translation is most valuable when it reduces short, high-frequency clarification work without forcing agents to abandon operational flow. It also revealed that adoption depends less on abstract enthusiasm for AI than on access speed, trust thresholds, mode fit, and clear boundaries for when translation support is safe enough to use.
Keywords: AI translation, multilingual service, frontline operations, gate agents, customer clarity, human-AI collaboration, workflow adoption, trust and safety, service design, airport experience.
* Note: specific details of this project have been omitted or modified for proprietary reasons.
Problem Space
International gate operations concentrate several forms of pressure into a small window: boarding timing, documentation checks, wayfinding, seat and group questions, last-minute rebooking concerns, and passenger anxiety. When a passenger does not speak English comfortably, even simple clarifications can become difficult to resolve quickly, especially when agents are already managing boarding groups, announcements, delays, document verification, and crowd movement.
Language support in this environment has historically been inconsistent. Agents often rely on whoever nearby may speak the passenger’s language, personal translation apps, gestures, paper documents, or repeated explanation. These methods can work in isolated cases, but they are not reliable as an operational system. They vary by flight, shift, agent tenure, language, crowd density, and the availability of informal help.
The challenge was not simply whether AI could translate words correctly. At the gate, translation must be fast enough to fit into live operations, accurate enough to avoid unsafe or misleading instructions, and simple enough that agents will use it at the moment of need rather than defaulting to faster informal workarounds. The key question was whether aiOla could become a practical part of gate work, rather than an additional tool agents had to manage.
This made the pilot a study of operational fit as much as translation quality. A tool that performs well in a demo may still fail in live conditions if it requires too many steps, struggles with noise, produces phrasing agents do not trust, or does not align with the difference between a short boarding clarification and a more nuanced customer conversation.
Research Design
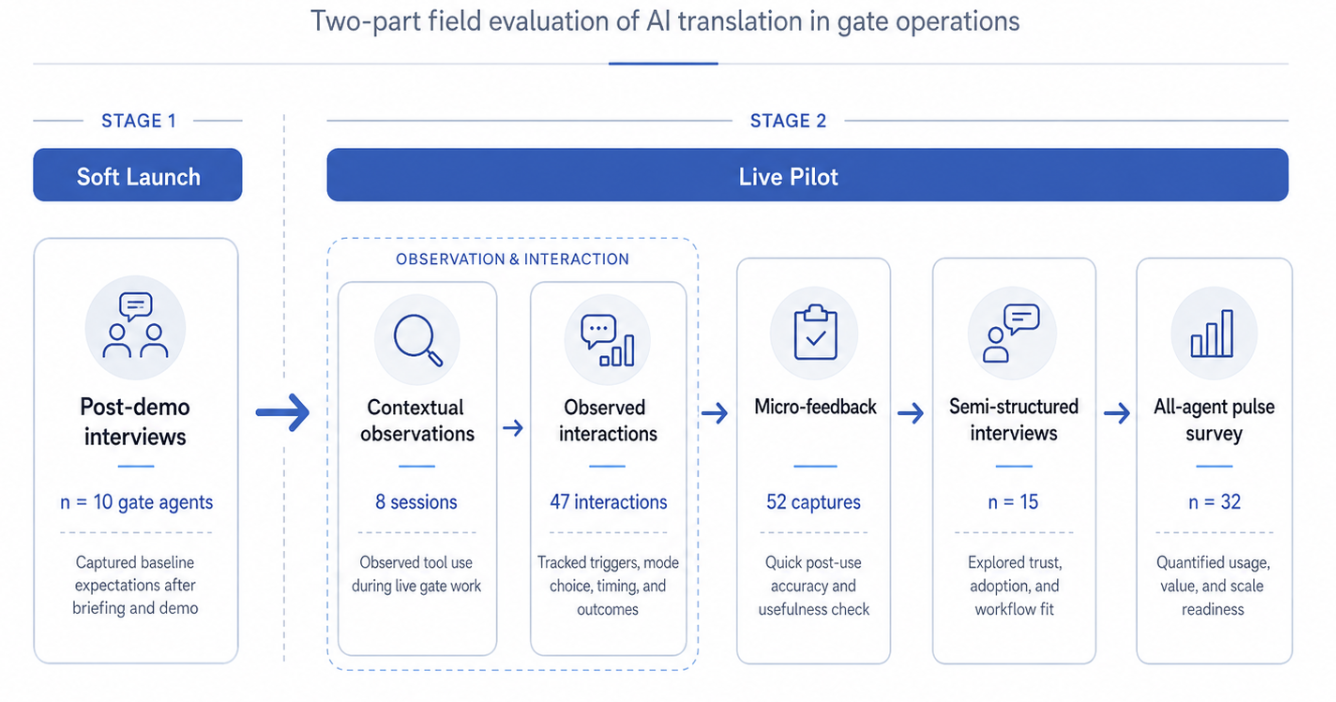
The research was conducted as a two-part field evaluation in an airport gate environment, beginning with a soft-launch briefing and demo discussion, followed by live gate evaluation during the pilot. The study focused on gate agents working international and domestic flights, with particular attention to high-diversity routes, peak boarding windows, documentation-related conversations, and moments where agents would otherwise rely on informal translation support.
The study combined five research inputs:
Soft-launch post-demo interviews with gate agents, n = 10
Contextual observations during live gate operations, n = 8 observation sessions
Observed translation-relevant interactions, n = 47
Post-use micro-feedback captures, n = 52
Semi-structured interviews with agents and leads, n = 15
All-agent pulse survey, n = 32 responses
The soft-launch interviews established agents’ baseline expectations after seeing the product demonstration: which workflows seemed promising, which modes appeared usable, and where agents anticipated breakdowns in live conditions. This phase helped identify likely adoption barriers before the tool was used with passengers, especially around device access, language selection, gate noise, and perceived differences between Quick Help and Conversational mode.
Live observation then examined how those expectations held up during real gate work. Observations focused on the full interaction sequence: what triggered the need for translation, how agents accessed the tool, which mode they selected, how long it took to produce usable output, whether the passenger appeared to understand, and whether agents completed the interaction or fell back to another method.
Micro-feedback captured short post-use impressions when operationally feasible, while semi-structured interviews explored trust, accuracy, fallback thresholds, training needs, and the perceived value of aiOla relative to existing practices. The all-agent pulse survey provided a broader read on usage frequency, perceived accuracy, speed, usability, and whether agents would support expansion to other airport locations.
Research Insights
1. The tool was strongest where translation functioned as operational clarification, not open-ended service recovery.
The clearest fit for aiOla was short, high-frequency gate work: confirming a gate location, explaining boarding group timing, directing a passenger to a document check, clarifying where to stand, or repeating a procedural instruction in the passenger’s preferred language. These interactions were already bounded. Agents knew what needed to be communicated, and the passenger’s need could usually be resolved with one or two turns.
In these cases, AI translation reduced the interpretive work agents normally carry. Rather than improvising with gestures, asking another employee for help, or typing into a personal app, agents could communicate a clear operational message and quickly check whether the passenger understood.
The weaker fit appeared in more complex or sensitive interactions. Documentation conversations, policy explanations, irregular operations, and emotionally charged customer issues often required more than translation. They required judgment, interpretation of airline policy, escalation awareness, and sensitivity to what the passenger may infer from the message. In those moments, agents were more cautious, and rightly so.
The practical implication is that aiOla should not be positioned as a general-purpose replacement for multilingual service support. Its strongest value is as a clarification layer for recurring, operationally bounded moments where speed and consistency matter most.
2. Adoption depended on whether the tool preserved gate momentum under load.
Agents did not evaluate aiOla in isolation. They evaluated it against the pace of gate work. During slower periods, agents were more willing to experiment, open the tool, select a language, try Conversational mode, and assess the result. During active boarding or peak crowding, the threshold changed. A small amount of friction—opening the app, finding the right phrase, confirming the language, waiting for output, adjusting volume—could be enough to push agents back toward gestures, quick English repetition, or informal help.
This created a central adoption pattern: the more operational pressure increased, the less tolerance agents had for setup work. The tool had to be available at the moment of need, not merely available somewhere in the ecosystem.
The distinction matters because gate operations are not evenly paced. A tool can appear usable in training and still fail during the moments where it could create the most value. In high-pressure conditions, agents do not want another system to manage; they want the interaction to move forward.
This suggests that scale readiness depends heavily on workflow integration. Persistent access, faster launch points, default language shortcuts for common routes, easier mode selection, and clearer audio/text delivery may matter as much as translation quality itself. For agents, usability is not a property of the interface alone. It is a property of the interface under boarding pressure.
3. Quick Help and Conversational mode supported different kinds of trust.
Agents treated Quick Help and Conversational mode as meaningfully different tools. Quick Help was understood as faster, safer, and better suited to high-pressure moments because the content was already bounded. Preset phrases reduced the risk that the agent would say something imprecise, and they fit recurring questions that agents already knew how to answer.
Conversational mode carried a different kind of value. It was more flexible and better suited to passenger-specific questions, but it also required agents to place more trust in speech recognition, translation accuracy, tone, and the tool’s ability to handle multi-turn exchanges. That made it more useful when the customer need was less predictable, but also more vulnerable to noise, misrecognition, or phrasing that did not sound operationally safe.3. Quick Help and Conversational mode supported different kinds of trust.
Agents treated Quick Help and Conversational mode as meaningfully different tools. Quick Help was understood as faster, safer, and better suited to high-pressure moments because the content was already bounded. Preset phrases reduced the risk that the agent would say something imprecise, and they fit recurring questions that agents already knew how to answer.
Conversational mode carried a different kind of value. It was more flexible and better suited to passenger-specific questions, but it also required agents to place more trust in speech recognition, translation accuracy, tone, and the tool’s ability to handle multi-turn exchanges. That made it more useful when the customer need was less predictable, but also more vulnerable to noise, misrecognition, or phrasing that did not sound operationally safe.
This difference reframes the product question. The goal is not to determine which mode is better overall, but to clarify what each mode is for. Quick Help supports consistency and speed when the airline already knows the message. Conversational mode supports flexibility when the passenger’s need cannot be anticipated in a phrase list.
For scale, the phrase library should be treated as an operational asset, not static content. It should be shaped around the highest-frequency passenger questions by route, boarding phase, and language context. Conversational mode, by contrast, requires training around how to phrase inputs, when to repeat or verify, and when to stop using AI and escalate.
4. Trust was shaped by boundaries, fallback rules, and training—not accuracy alone.
Agents were not simply asking whether the translation was “right.” They were asking whether it was safe to use in a specific operational moment. A translation could be mostly accurate and still feel risky if it sounded too formal, omitted context, mishandled airline terminology, or left room for misunderstanding around documentation, boarding eligibility, or next steps.
This is especially important because gate agents are accountable for the passenger interaction even when the AI produces the translation. If a customer misunderstands boarding timing, document requirements, or where to go next, the operational consequences still return to the agent and the airline.
The research therefore points to training as a central part of the product experience. Agents need more than a demo. They need clear guidance on where aiOla is appropriate, which types of interactions should remain human-led or escalated, how to verify passenger understanding, and what to do when the translation feels wrong.
This also changes how translation quality should be evaluated. Accuracy scores are necessary but insufficient. The more important operational question is whether the tool helps agents produce messages that are clear, polite, contextually appropriate, and safe within the constraints of gate work.
Strategic Impact
The study reframed aiOla from a translation capability to an operational support tool. Its value is not simply that it can translate across languages, but that it can reduce avoidable friction in moments where language barriers slow down gate flow, increase agent burden, or create uncertainty for passengers who need fast clarification.
For near-term rollout, the research supports a targeted deployment strategy rather than broad, undifferentiated expansion. The strongest candidates are gates and routes with frequent multilingual interactions, recurring wayfinding or boarding questions, and enough operational consistency to build route-specific phrase sets. These are the contexts where Quick Help can provide immediate value while Conversational mode matures through training and workflow refinement.
The findings also clarify what must improve before scale. Access has to be faster. Phrase libraries need to reflect real gate language. Training must establish clear use and escalation boundaries. Audio and text delivery must work in noisy, crowded environments. Supervisors and leads need a shared understanding of when the tool supports operations and when other forms of assistance remain necessary.
More broadly, the pilot suggests that AI adoption in frontline service environments is governed by the same constraints that shape other day-of-travel tools: timing, trust, clarity, and fit within the physical workflow. Agents will use AI when it helps them preserve forward motion. They will avoid it when it adds interpretation work, slows the interaction, or leaves them uncertain about whether the output is safe enough to stand behind.
The strategic opportunity, then, is not to make gate agents “use AI.” It is to design multilingual support so that agents can resolve common passenger needs more consistently, while retaining the judgment and fallback options required in high-stakes service moments. Done well, aiOla can help establish a more scalable model for multilingual assistance at the gate—one that improves clarity for passengers, reduces informal workarounds for agents, and creates a stronger foundation for inclusive service across airport locations.